

In this article, we’ll be going to learn what sharding means in the context of databases, why we need it, and what are its pros and cons. Sharding means breaking down a big dataset into small disjoint subsets. Now, how you break it down is more of an implementation detail. You can decide it using what is called the sharding key.
But why break down a dataset? What benefit will it give?
Let’s say you are a software developer who wants to send out a newsletter about what is going on with the tech world to people. In order to send those letters, you will want to store interested people’s names and email addresses.
A dataset being split into multiple smaller subsets.
Let’s say you opt-in for a SQL database to store their data, and you decide to run the SQL server on your own computer. You had, let’s say, 100 GB of space available, and you are confident that 100 GB is more than enough.
People started subscribing to your newsletter, and whenever someone subscribed, their information gets stored in your DB. You are one of the happiest people alive because so many people are interested in your newsletter.
But one day, you get a warning that you are running out of disk space. Only 299 MB is left out of 100 GB.
You start panicking; after all, you have spent so much effort putting in your content, but if all the space is filled, you won’t be able to store new user details.
But then you realised you are a software developer, so you thought of two options:- Migrate your data to a larger disk (1TB). (Vertical Scaling)
- Break your data into chunks and store it on multiple servers. (Horizontal Scaling)
At first, you might think, well, migrating the data seems a reasonable and easy option. But what seems easy now can become a nightmare later.Let’s think about it why migrating the data might not be a good option.
As the size of data keeps on increasing, this leads to slow queries and a single point of failure. Why?
Let us take a small example. Suppose we have stored all our data on one DB that can store 100,000 rows of content or, in our case, 100,000 email addresses.
Also, let’s say our server is capable of querying 10 rows per second (which, to be honest, is pretty damn slow).
Say, you want to fetch the email address of a person whose name = ‘Mathew’. We are assuming that there is no such thing as indexing. How long will it take for our server to give us the result in the worst case?
100,000 / 10 = 10,000 sec = 166.67 hr = 6.94 daysNow let’s divide this data into smaller disjoint subsets and see if we are able to speed up the query time.
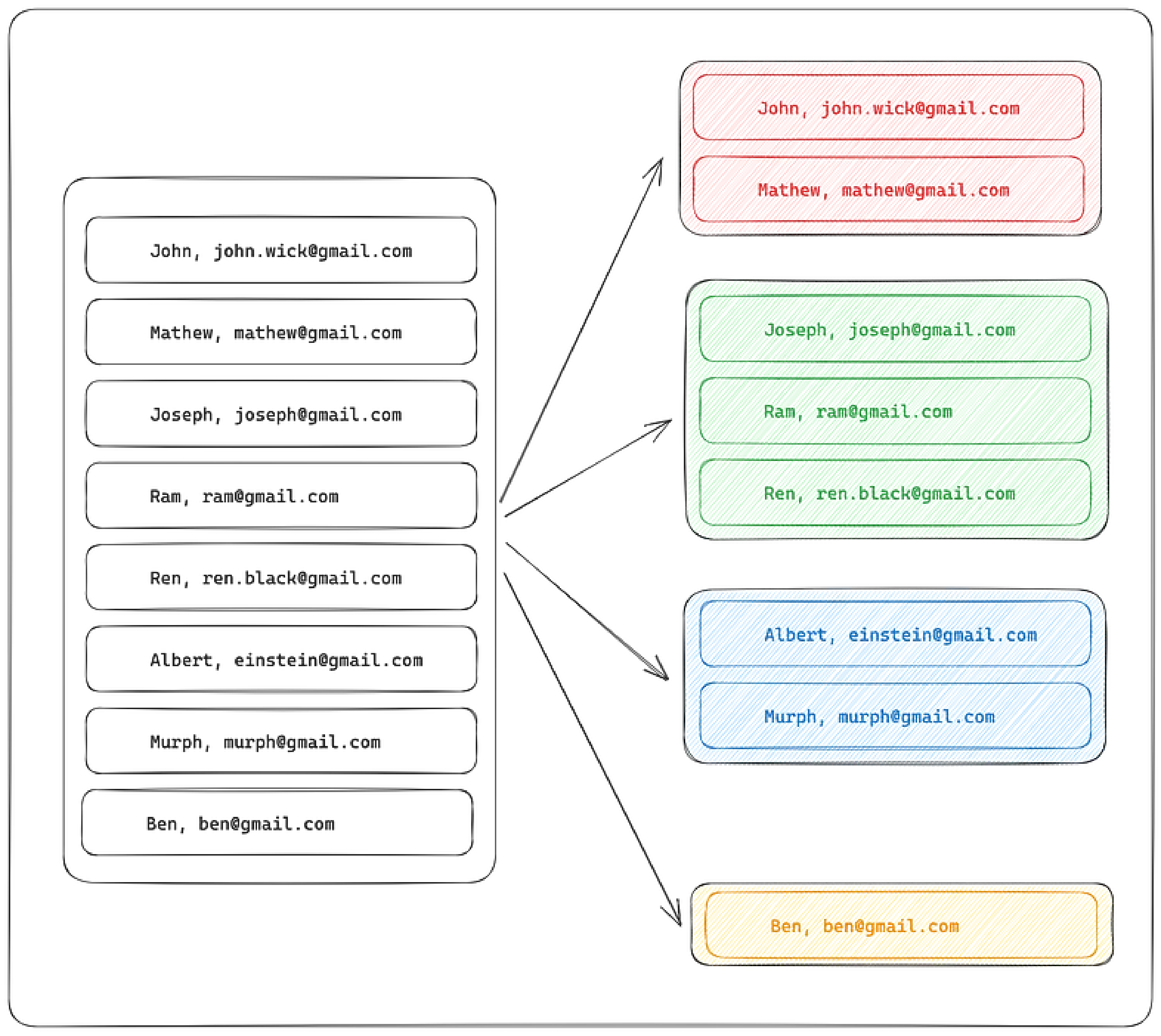
For this example, let’s say we decided to split the data into 5 different parts and store them on different servers (DB). Using some simple math, each server will now have 100,000 / 5 = 20,000 rows of data.
Now we ran the same query to fetch the email address of a person whose name = ‘mathew’. Since the data is distributed to 5 different servers. All those servers can run this query independently. (Note: we need not run the query on all servers; we can make use of a sharding key to know on which server our data is and can only run the query on that server. But for the sake of simplicity, let’s not go that way).
Data getting routed to shard based on its content.
Let’s denote the servers by S1, S2, S3, S4, and S5. Since we assume there is only one record having the name = Mathew, the record will be present on only one server. For this example, let’s assume it is present on S5.
Since each server is capable of querying 10 rows per second.
S1 → 20,000 / 10 = 2,000s = 33.33hrs = 1.38 days (Not found)S2 → 20,000 / 10 = 2,000s = 33.33hrs = 1.38 days (Not found)
S3 → 20,000 / 10 = 2,000s = 33.33hrs = 1.38 days (Not found)
S4 → 20,000 / 10 = 2,000s = 33.33hrs = 1.38 days (Not found)
S5 → 20,000 / 10 = 2,000s = 33.33hrs = 1.38 days (found)
You see, we went from 6.94 days to only 1.38 days.
Since your newsletter is getting viral, you decided to no longer store the data on your own pc but leave this to the professionals. By professionals, we mean cloud services, those who can automatically take care of splitting, indexing (based on query patterns), and keeping multiple copies of the shard so that even if one shard goes down, your data will still be safe.
But all this comes with an overhead and complexity. Let me explain why.Since we divided our dataset into five shards, what will happen if new data comes? To which shard will it be saved?
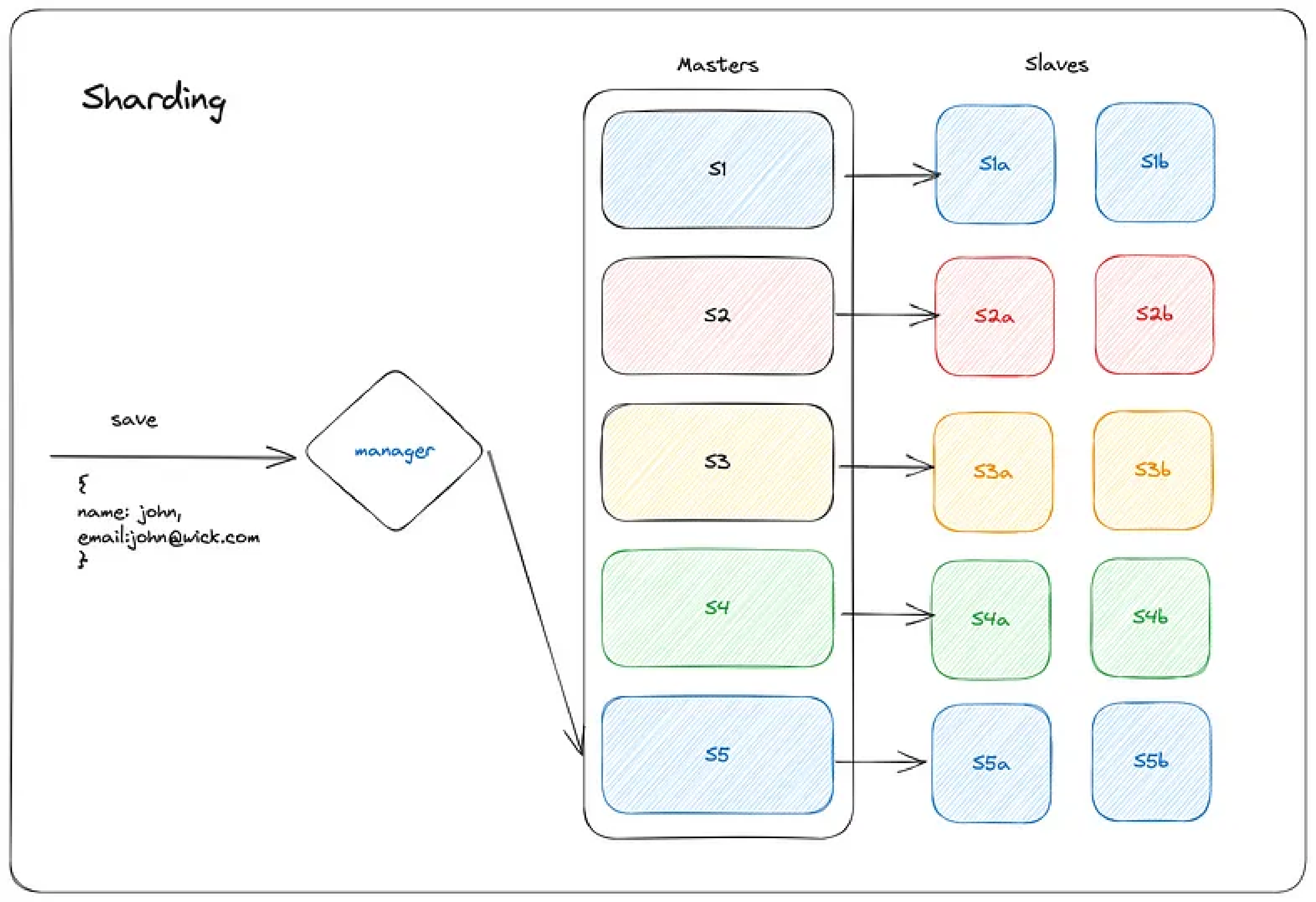
This is where the sharding key concept comes into play. The data first goes through a manager, which takes the data and outputs the server number.
(name: “john”, email: “john.wick@keanu.com”) → (manager) → S3This manager will also need to serve the read request; as mentioned earlier, if we want to search for an email belonging to John, we do not want to run the query on all shards but S3.
(name: “john”, email: ?) → (manager) → Search S3.The way manager works can vary; it can be as simple as round-robin; whenever a write request comes, it forwards it to the next server and saves that info somewhere so that when the next time someone wants to read that data, it can simply lookup and redirect the request to that server.
Or, it can simply use hashing (consistent hashing) to find on which server to direct the write or read request.
For us to avoid a single point of failure, we can have master-slave architecture. Where the master will only take the write requests, and all the slaves will keep on updating their data based on what the master has.
If, due to some reason master fails, the slaves will elect a master among themselves based on which slave has the most up to dated data.
I think that will be it for this article; if you have any doubts about the examples I gave or anything, let me know in the comments, and I’ll be happy to address them.
Finally, I hope this article gave you an overall idea of what sharding means and why it is a better alternative to just increasing the size of your DB.
References: