

Let's dive into the fascinating world of IPFS, where files travel across the universe like cosmic voyagers, and the internet becomes a decentralized playground of wonders!
Imagine a future where the Internet is no longer dependent on a single server or controlled by a handful of power entities. Enter IPFS, the InterPlanetary File System, a revolutionary protocol that's reshaping the way we store, share and access information.
IPFS, stands for InterPlanetary File System. It is a peer-to-peer network that allows users to store and access files without relying on a centralized server
At the heart of IPFS lies content addressing, a mind-bending concept that replaces traditional URLs with unique cosmic passports called content identifiers (CIDs).
In IPFS, all forms of data are addressed by their content instead of their location. Each file is assigned unique identifier (CID), which is derived from the file's content.
CID serves as a cryptographic hash of the data and remains constant across the network, ensuring that the content can be located and verified.
Let's understand how it works
IPFS is based on several technologies and concepts, including Distributed Hash Tables (DHTs), MerkelDAGs, and the Bitswap Protocol. Let's go through each of them to understand them better.
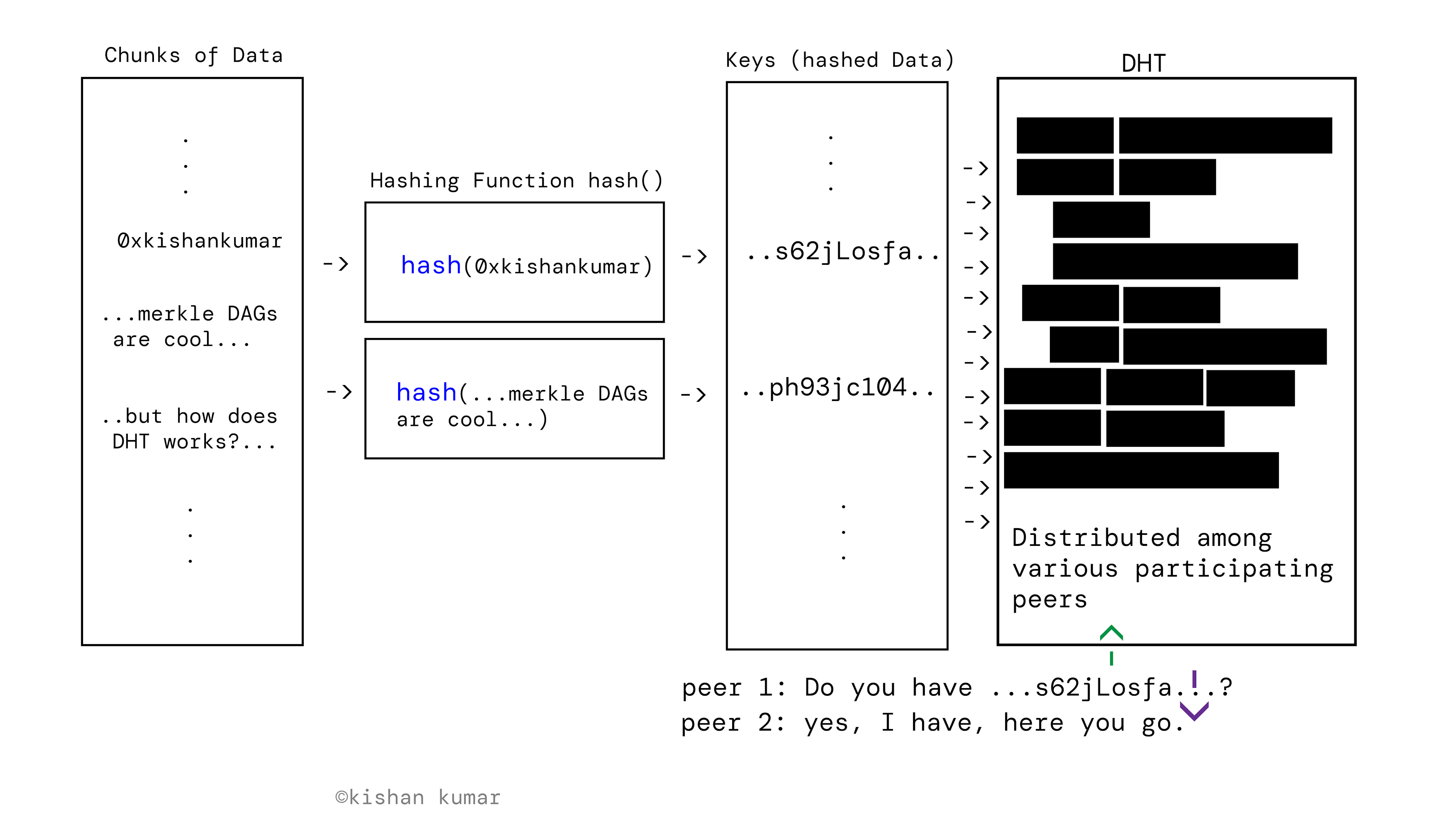
Distributed Hash Table
- Distributed Hash Tables: DHTs are a decentralized data structure that allows nodes to store and retrieve data in a distributed manner. In IPFS, each file and its metadata are given a unique hash, which is used as the key in the DHT. This allows nodes (sort of servers) to find and retrieve files without relying on a central server.
- MerkleDAGs: IPFS uses MerkleDAGs, a tree-like data structure (Directed Acyclic Graph), to represent files and directories. Each node (not server) in the MerkleDAG represent a piece of data and has a unique hash based on its content. This ensures data integrity and allows for efficient data deduplication, as identical content will have the same hash. Nodes are linked through their CIDs, forming a hierarchical structure similar to a filesystem tree.
- BitSwap Protocol: It is a P2P file exchange protocol inspired by BitTorrent. It allows nodes to exchange blocks of data with each other, ensuring that content is distributed efficiently across the network.
- You add the file to your local IPFS node, which breaks it into smaller blocks and creates a MerkleDAG representing the file structure. But, wait, how do I setup an IPFS node? This sounds way too complex man! Trust me, this is not as complex as it may seem, we'll come to this part soon. But for now, let's go with the flow.
- Each block is given a unique hash based on its content.
- When someone wants to download the file, their IPFS node requests the blocks from other nodes in the network using the BitSwap protocol.
- The requested blocks are reassembled into the original file, and the MerkleDAG ensures the data integrity
Setting Up IPFS Locally
- Install IPFS: you need to download and install the IPFS software on your computer. Depending upon the OS you'll get the package from their official website:https://docs.ipfs.io/install/command-line"
- Initialise: After installing it, you'll need to initialize the IPFS. Open a terminal (or Command Prompt) and run the following command to initialize your IPFS nodeipfs init
This command will create a new IPFS repository in your home directory and generate a unique peer identifty for your node.
- Start the IPFS daemon: Run the following command:ipfs daemon
This will launch the IPFS daemon, which will keep running in the background and allow your node to connect to the IPFS network.
- Add a file to IPFS: To share a file, you need to add it to your local IPFS node. Use the following command, replacing "path/to/your/file" with the actual path to the file you want to share:ipfs add path/to/your/file
This command will output a unique hash (also known as the Content Identifier or CID) that represents your file in the IPFS network. Make a note of this hash, as you'll need it to share the file with others
- Share the file: To share the file with others, simply provide them with the CID you obtained. They can use this CID to access the file through their own IPFS node or an IPFS gateway (e.g., https://ipfs.io).
That's it! You've successfully set up a local IPFS node and share a file. Keep in mind that your IPFS node needs to be running (i.e., the IPFS daemon should be active) for others to access the file you've shared
Comparison with traditional filesystems
Traditional filesystems rely on a centralized server to store and serve files. This can lead to several issues, such as single point of failures, censorship, and inefficient data distribution. In contrast, IPFS offers the following advantages:
- Decentralization: IPFS is a P2P network, which means there is no central authority controlling the data. This makes it more resilient to failures and censorship.
- Data Integrity: The use of content-addressing and MerkleDAGs ensures that data is not tampered with and remains consistent across the network.
- Deduplication: Identical content is stored only once in the network, reducing storage requirements and improving efficiency
- Caching and Offline access: IPFS nodes can cache frequently accessed content, reducing latency and allowing for offline access to data
- Scalability: IPFS can handle large amounts of data and a high number of users without relying on centralized servers, making it more scalable than traditional filesystems.
Disadvantages of IPFS over Traditional Filesystems
- Retrieval Speed: While IPFS offers benefits in terms of data redundancy and availability, the retrieval speed of files can vary depending on the network and the popularity of the content. As files are distributed across multiple nodes, it may take more time to retrieve files compared to centralized systems where files are stored in a single location.
- Storage Space: Due to the distributed nature of IPFS, every node participating in the network needs to store a certain amount of data. This can result in higher storage requirements for nodes compared to traditional systems where data is typically stored in a centralized location.
- Dependence on Network Availability: IPFS relies on a network of interconnected nodes for file retrieval. If the network experiences widespread connectivity issues or the number of active nodes decreases significantly, it can impact the availability and accessibility of files.
- Learning Curve: IPFS introduces new concepts and terminology, such as CIDs, MerkleDAGs, and DHTs. Understanding and working with these concepts may require a learning curve for developers and users who are familiar with traditional filesystems.
It's important to note that the IPFS is not intended to replace traditional filesystems entirely but rather offers a complementary approach to file storage and sharing.
By combining the strength of IPFS with traditional filesystems, it's possible to harness the benefits of both worlds and create more robust and versatile systems for data storage and distribution
IPFS was invented by Juan Benet, an American computer scientist and entrepreneur. He is the founder and CEO of Protocol Labs. He introduced IPFS in 2014 as a solution to address the limitations of traditional client-server architecture and to create a more decentralized and resilient infrastructure.
References: